library(microbenchmark) # to benchmark and plot
library(bench) # alternate benchmark
library(ggplot2) # to support autoplot
set.seed(42)
mbm <- microbenchmark # shortcut used belowBenchmarking cpp11armadillo and RcppArmadillo: But Correctly This Time
Introduction
Armadillo is fabulous C++ library making (performant) linear algebra operations easily accessible from C++. Our R package RcppArmadillo has long supported it for the statistical research community via the RcppArmadillo package which, as of September 2025, is used by over 1200 packages at CRAN. There is also ‘another’ package cpp11armadillo using Armadillo which in a recent peer-reviewed paper uses a seriously deficient (!!) benchmark setup to conclude that the latter is better.
And not to spoil it: It is not better. RcppArmadillo wins on features and wins or ties on performance. This note can show this as the author included the code of the benchmarks used in the paper in the package and repository. So we can retake them, repair them as needed (more on that below) and demonstrate that with both minmal and obvious (if you ever used RcppArmadillo) changes the purpoted performance gain vanishes.
We should add that these are not great benchmarks. They consist on calling just one Armadillo function and one (compound) expression. Hence, what they measure is essentially only the glue code. Padding the entrant you want to compare against with unnecessary code (see below) is obviously going to tilt the comparison: when you race two vehicles, you do not also put some extra concrete blocks in the trunk of your competitor.
Adding to this, the motivation for cpp11armadillo remains bewildering. On both the CRAN page and the repository it lists of number of bullet points some of which are plain false (as this note demonstrates below) and others are plain amusing: “Using UTF-8 strings everywhere.” Really? That is interesting because Armadillo only supports (signed or unsiged) integer values, floating point aka double precision in different bitsizes as well as complex. But no strings anywhere so clearly no utf8 either. Maybe the copying from another repo was just too easy here… Another claim is made regarding ‘smaller memory footprint’ which we debunk below. This leaves one quasi-religious argument regarding the choice of license for RcppArmadillo which, not coincidentally, is the same license R uses. So if there were any viralness (to be plain: there is not as no code is copied) then it would also apply to the other 1200+ packages which use RcppArmadillo. But it does not, and many of these use licenses of their choice: BSD, MIT, GPL variants, … All is good, all is permitted as long as these are recognized open source licenses (and CRAN checks on that too). Leaves the final and maybe most bizarre claim about “vendoring” which is a little technical and I fear yet again misused: as RcppArmadillo is a header-only package that does not link to Armadillo or anything else besides R or libraries R uses already, there is no new net deployment requirement. Anyway…
And in any event, choice is good, and different packages can try different approaches. But it would be preferable to keep it to correct and verifiable statements, and the posted benchmarks are not as we detail here by looking at the two contained in the repository.
Lastly, this note and it repository can be seen as a follow-up on an earlier repository ldasb. Here the acronym expands to Lies, Damned Lies, And Selective Benchmarks; the repository is an attempt at clarifying another earlier attempt at obfuscation via incorrect / inappropriate benchmarks.
Preliminaries
We load some R packages used below, set the random number generator seed for reproducibility and define an alias used below in order to keep the line length down.
Benchmark 1: Eigen Values
cpp11armadillo Version
The first benchmark calls the eig_sym() from Armadillo. For the cpp11armadillo package the code is fairly straightforward and contains one conversion on input from an cpp11 matrix to arma::mat, and similarly back from arma::colvec to a cpp11 vector.
#include <cpp11.hpp>
#include <cpp11armadillo.hpp>
using namespace cpp11;
using namespace arma;
[[cpp11::register]]
doubles bench_eig_cpp11armadillo_(const doubles_matrix<>& m) {
mat M = as_Mat(m);
colvec Y = eig_sym(M);
return as_doubles(Y);
}Incorrect RcppArmadillo Version
Now, the code proposed for RcppArmadillo appears inspired by a similar idea:
#include <RcppArmadillo.h>
using namespace Rcpp;
using namespace arma;
// [[Rcpp::export]]
NumericVector bench_eig_rcpparmadillo_incorrect_(const NumericMatrix& m) {
mat M = as<mat>(m);
colvec Y = eig_sym(M);
return wrap(Y);
}Repaired RcppArmadillo Version
But this is not how anyone familiar with RcppArmadillo would write it: one key characteristic is that we can use Armadillo on the interface for both and output! No (forced) conversion needed, and in fact, done as done here it will be inefficient as it forces a copy instead of reusing the underlying data. So a better version, which also takes advantage of the fact that we do not need to preserve the RNG when we do not used RNG code, is just
#include <RcppArmadillo/Lightest>
// [[Rcpp::export(rng=FALSE)]]
arma::vec bench_eig_rcpparmadillo_fixed_(const arma::mat& m) {
return eig_sym(m);
}We literally just call eig_sym() as RcppArmadillo takes care of both the input and the output conversion. This reduces the function to a one clear and obvious one-liner, or even one-statement: we call eig_sym() with a (constant) arma::mat as input returning an arma::vec. This is how Armadillo is set up, and how RcppArmadillo provides access. Without any additional cognitive overload from going via yet another type system.
(As an aside, using #include <RcppArmadillo/Lightest>, a newer entry point using #include <Rcpp/Lightest> only reduces compile time, not run-time. But it does not hurt. We also, and on purpose, skip the using namespace ... directives which are generally avoided by experienced programmers.)
Benchmarks
Needless to say, when comparing this incorrect RcppArmadillo approach with a corrected one, the difference is clear. In fact, the corrected version is also faster than the cpp11armadillo version by about 10 to 15%.
V <- rnorm(1e7)
M <- t(V) %*% V
bm <- mbm(cpp11 = armabenchmarks::bench_eig_cpp11armadillo_(M),
rcppBad = armabenchmarks::bench_eig_rcpparmadillo_incorrect_(M),
rcppFixed = armabenchmarks::bench_eig_rcpparmadillo_fixed_(M),
times=10000)
print(bm, order="median")Unit: nanoseconds
expr min lq mean median uq max neval cld
rcppFixed 390 421 615.163 441 461 26490 10000 a
cpp11 450 491 667.673 501 511 52850 10000 a
rcppBad 581 611 3855.515 631 651 29705707 10000 aResults will vary by compiler or computer, but on my machine the corrected version using RcppArmadillo takes about ten to fifteen percent less time than the cpp11armadillo. And, needless to say, even way less time than the incorrect version from the peer-reviewed paper which adds needless and (as seen here) costly extra copies.
autoplot(bm, order="median") +
ggtitle(label=paste("Armadillo Packages Benchmark Comparison:",
"RcppArmadillo versus cpp11armadillo"),
subtitle=paste("Using symmetric Eigen decomposition",
"of 1e7 x 1e7 matrix")) +
tinythemes::theme_ipsum_rc()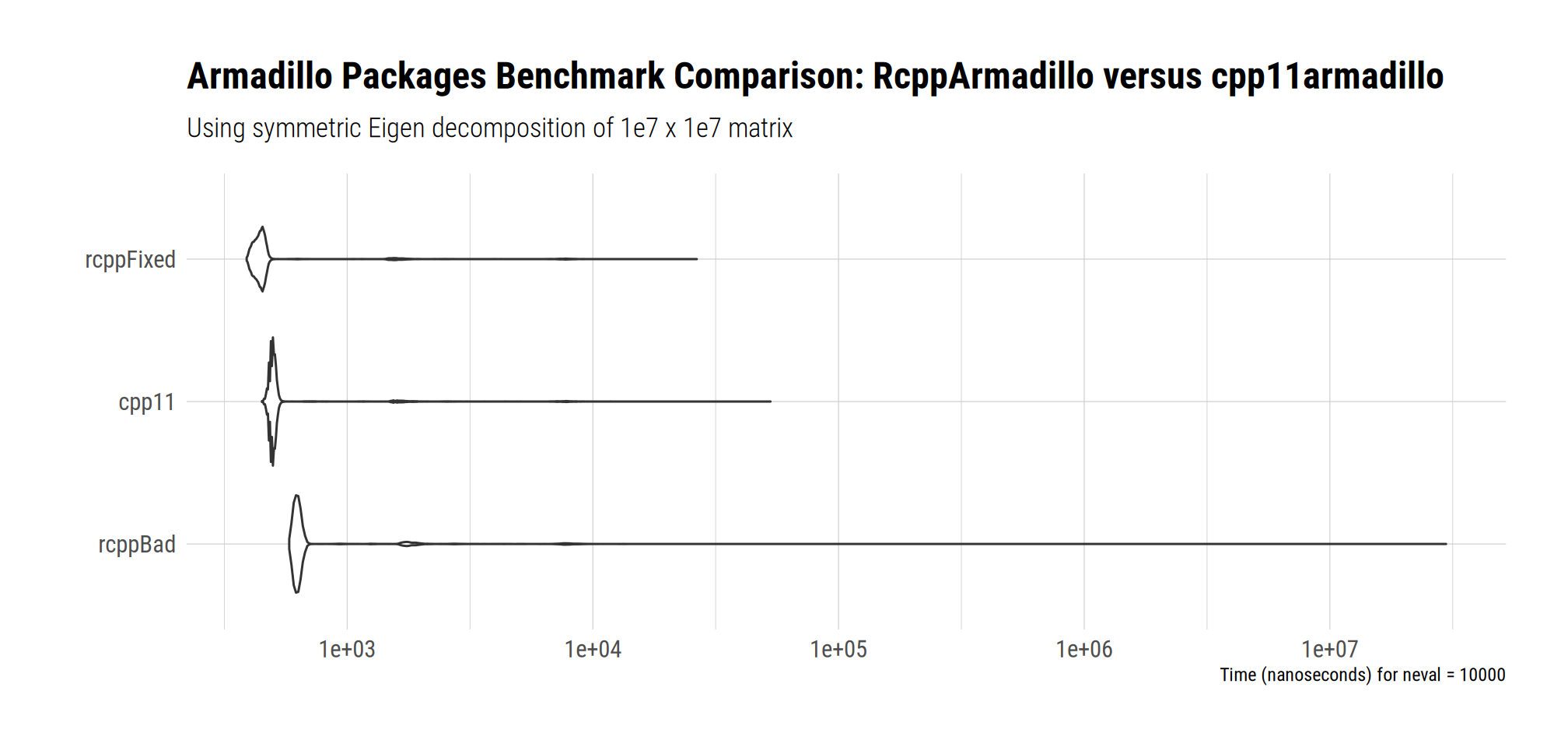
We can also look at this via bench::mark() which usually displays memory usage (though in this quarto notebook that information is hidden). Running interactively shows now extra allocations for either method: both just call Armadillo.
bm <- mark(cpp11 = armabenchmarks::bench_eig_cpp11armadillo_(M),
rcppBad = armabenchmarks::bench_eig_rcpparmadillo_incorrect_(M),
rcppFixed = armabenchmarks::bench_eig_rcpparmadillo_fixed_(M),
check=FALSE) # 'incorrect' returns a matrix not a vector
bm# A tibble: 3 × 13
expression min median `itr/sec` mem_alloc `gc/sec` n_itr n_gc total_time result memory time gc
<bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl> <int> <dbl> <bch:tm> <list> <list> <list> <list>
1 cpp11 470ns 491ns 1939645. 0B 0 10000 0 5.16ms <NULL> <Rprofmem [0 × 3]> <bench_tm [10,000]> <tibble [10,000 × 3]>
2 rcppBad 591ns 631ns 1194357. 0B 0 10000 0 8.37ms <NULL> <Rprofmem [0 × 3]> <bench_tm [10,000]> <tibble [10,000 × 3]>
3 rcppFixed 410ns 440ns 1793137. 0B 0 10000 0 5.58ms <NULL> <Rprofmem [0 × 3]> <bench_tm [10,000]> <tibble [10,000 × 3]>No memory allocations in either version, no difference between version. Hence no credible claim for ‘smaller memory footprint’ in cpp11armadillo.
We can also plot this, ordered by time:
bm |>
dplyr::mutate(expression =
forcats::fct_reorder(as.character(expression),
min, .desc = TRUE)) |>
bench::as_bench_mark() |>
autoplot() +
ggtitle(label=paste("Armadillo Packages Benchmark Comparison:",
"RcppArmadillo versus cpp11armadillo"),
subtitle=paste("Using symmetric Eigen decomposition of",
"1e7 x 1e7 matrix")) +
tinythemes::theme_ipsum_rc()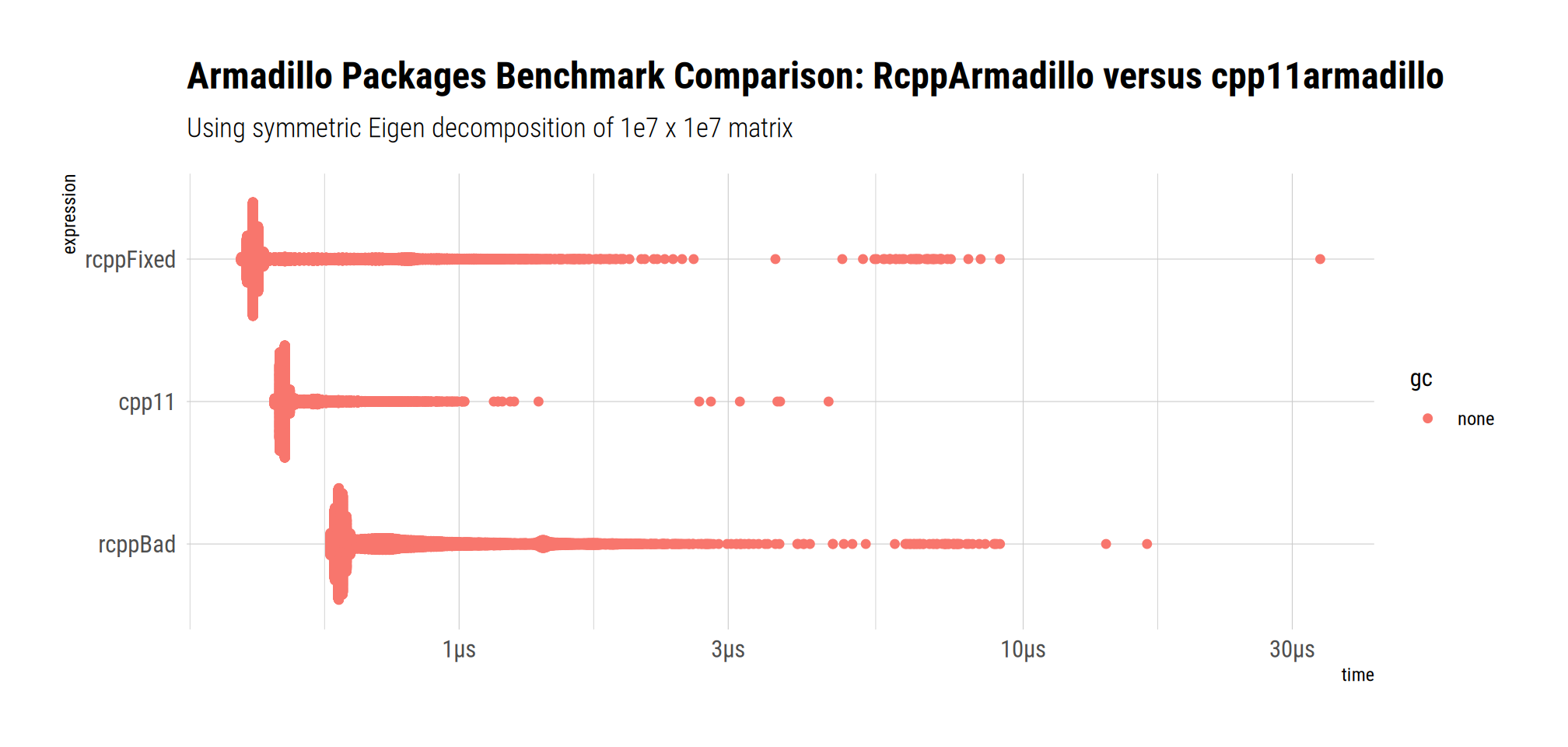
Again, the correctly used RcppArmadillo expression is the fastest.
Benchmark 2: Compound Expression
The second benchmark evaluated a single matrix expression, something Armadillo is really good at because it generally manages to avoid creation of temporary object by relying on complex (and clever) template meta-programming.
cpp11armadillo Version
The cpp11armadillo version is again straightforward but once again needs to transform input and output values.
[[cpp11::register]]
double bench_multi_cpp11armadillo_(const doubles& p, const doubles& q,
const doubles& r) {
colvec P = as_Col(p);
colvec Q = as_Col(q);
colvec R = as_Col(r);
return as_scalar(trans(P) * inv(diagmat(Q)) * R);
}Incorrect RcppArmadillo Version
The (incorrect) RcppArmadillo version deployed in the published benchmark once again force object copies (once again ignoring argument copy_aux_mem clearly described in the Armadillo documentation), and also incurring the (safe, but avoidable) cost of storing and resetting the random number generator state.
// [[Rcpp::export]]
double bench_multi_rcpparmadillo_incorrect_(const NumericVector& p,
const NumericVector& q,
const NumericVector& r) {
colvec P = as<colvec>(p);
colvec Q = as<colvec>(q);
colvec R = as<colvec>(r);
return as_scalar(trans(P) * inv(diagmat(Q)) * R);
}Repaired RcppArmadillo Version
Avoiding these two obvious shortcomings, the RcppArmadillo becomes shorter.
// [[Rcpp::export(rng=FALSE)]]
double bench_multi_rcpparmadillo_fixed_(const arma::vec& p, const arma::vec& q,
const arma::vec& r) {
return arma::as_scalar(arma::trans(p) * arma::inv(arma::diagmat(q)) * r);
}Benchmarks
Setting up the second benchmark is similar to the segement above. There is essentially no difference between the two packages once we looked at corrected RcppArmadillo code. Over repeated runs the order between the two (correctly used) methods changes more or less randomly: they are of equivalent speed.
However, the incorrect approach used in the publication is obviously worse, and by a lot. The published version casts RcppArmadillo into a bad light, as does so only because of its incorrect / inefficient use.
n <- 1e5
p <- runif(n)
q <- runif(n)
r <- runif(n)
bm <- mbm(cpp11 = armabenchmarks::bench_multi_cpp11armadillo_(p,q,r),
rcppBad = armabenchmarks::bench_multi_rcpparmadillo_incorrect_(p,q,r),
rcppFixed = armabenchmarks::bench_multi_rcpparmadillo_fixed_(p,q,r),
times=10000)
print(bm, order="median")Unit: microseconds
expr min lq mean median uq max neval cld
cpp11 37.250 38.392 43.2594 39.454 41.2020 1605.68 10000 a
rcppFixed 37.280 38.432 43.0935 39.544 41.7185 1080.55 10000 a
rcppBad 109.435 111.720 138.7377 112.341 120.0600 2197.72 10000 bWhen plotted, the gap to the incorrect version becomes very apparent.
autoplot(bm, order="median") +
ggtitle(label=paste("Armadillo Packages Benchmark Comparison:",
"RcppArmadillo versus cpp11armadillo"),
subtitle=paste("Using compound expression on",
"1e5-vectors")) +
tinythemes::theme_ipsum_rc()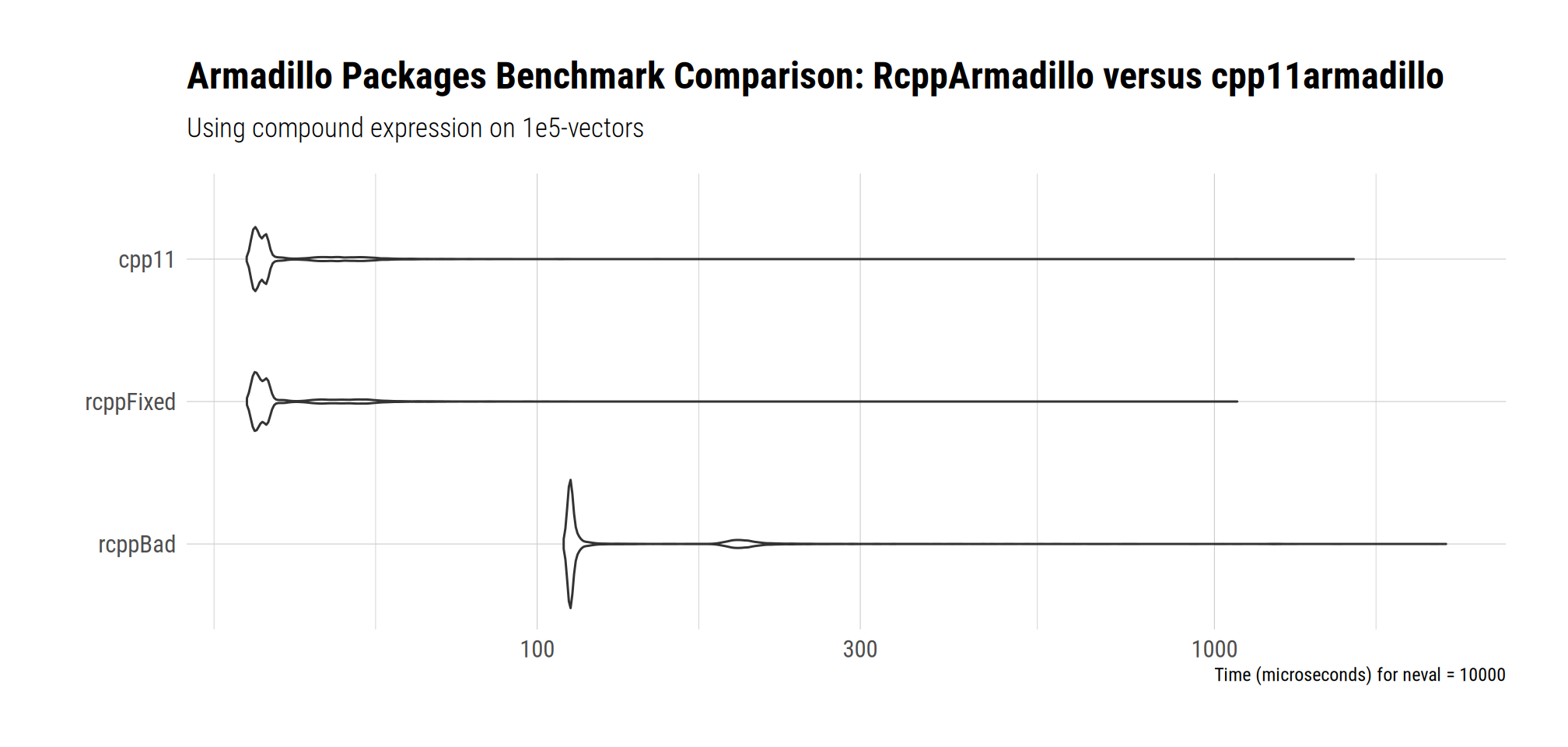
We can use the alternate benchmarking package too.
bm <- mark(cpp11 = armabenchmarks::bench_multi_cpp11armadillo_(p,q,r),
rcppBad = armabenchmarks::bench_multi_rcpparmadillo_incorrect_(p,q,r),
rcppFixed = armabenchmarks::bench_multi_rcpparmadillo_fixed_(p,q,r))
print(bm)# A tibble: 3 × 13
expression min median `itr/sec` mem_alloc `gc/sec` n_itr n_gc total_time result memory time gc
<bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl> <int> <dbl> <bch:tm> <list> <list> <list> <list>
1 cpp11 37.9µs 39.3µs 23237. 0B 0 10000 0 430ms <dbl [1]> <Rprofmem [0 × 3]> <bench_tm [10,000]> <tibble [10,000 × 3]>
2 rcppBad 106.8µs 111.6µs 7553. 0B 0 3777 0 500ms <dbl [1]> <Rprofmem [0 × 3]> <bench_tm [3,777]> <tibble [3,777 × 3]>
3 rcppFixed 37.7µs 38.7µs 23925. 0B 0 10000 0 418ms <dbl [1]> <Rprofmem [0 × 3]> <bench_tm [10,000]> <tibble [10,000 × 3]>Again, no memory allocations, and no memory-use difference.
bm |>
dplyr::mutate(expression = forcats::fct_reorder(as.character(expression),
min, .desc = TRUE)) |>
bench::as_bench_mark() |>
autoplot() +
ggtitle(label=paste("Armadillo Packages Benchmark Comparison:",
"RcppArmadillo versus cpp11armadillo"),
subtitle=paste("Using matrix operations operations",
"on three 1e5-sized vectors")) +
tinythemes::theme_ipsum_rc()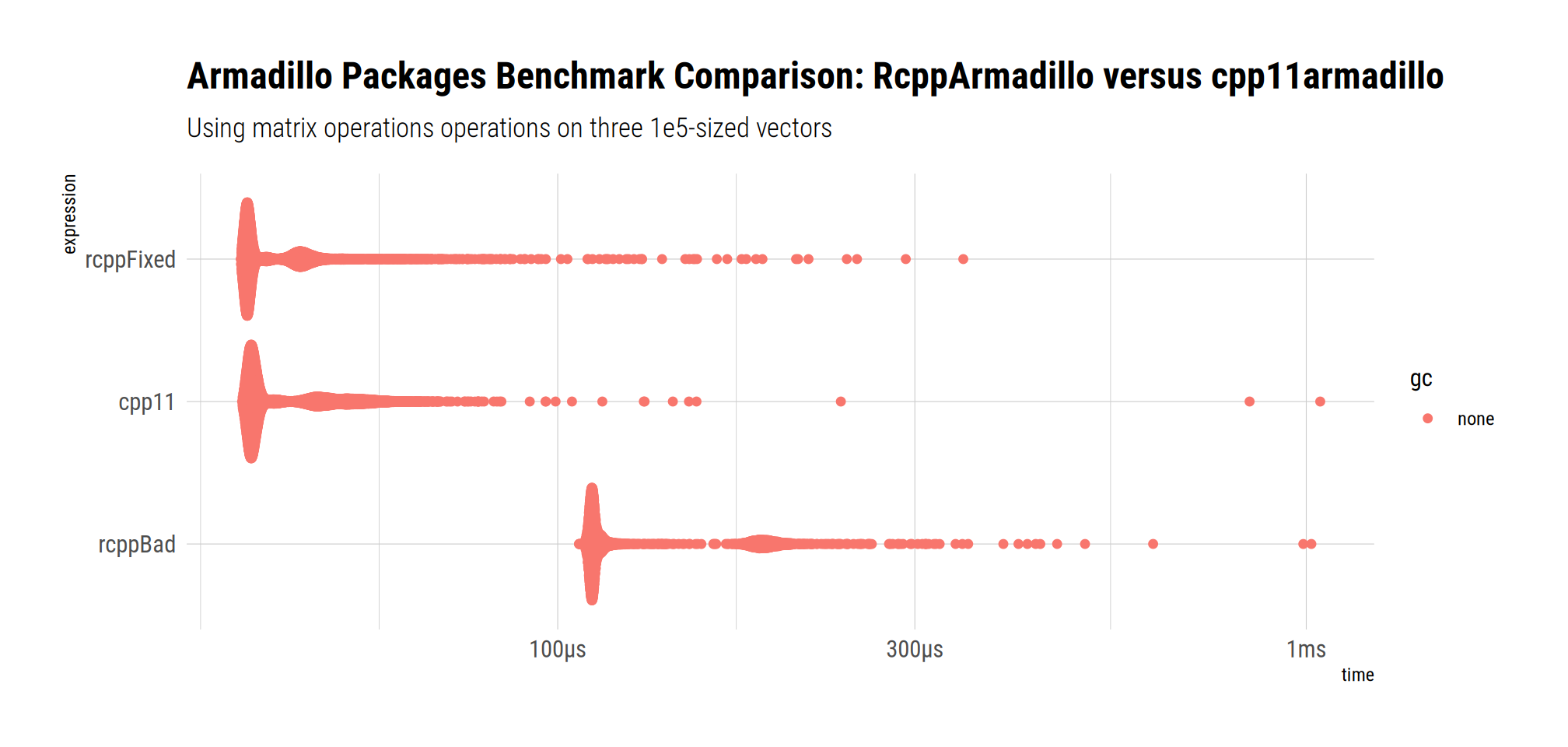
Conclusion
RcppArmadillo offers more functionality than cpp11armadillo, and leads to shorter and more idiomatic code that is easier to use and work with. Despite claims in the published paper, there is neither a speed nor a memory use penality when relying on RcppArmadillo. By repairing the (public) benchmark code we find RcppArmadillo to in one case outperform, and in the other case tie, the challenger cpp11armadillo—on benchmarks chosen by the challenger. Analysis that relies on Armadillo to extend the facilities offered by R itself can use either package, but might be well served by relying on the much-more widely used RcppArmadillo package.